flowchart
HTML
HTML --> HEAD
HEAD --> TITLE
HTML --> BODY
BODY --> H1 & P1[P] & P2[P] & UL & P3[P]
UL --> LI1[LI] & LI2[LI]
LI1 --> A1[A]
LI2 --> A2[A]
P3[P] --> B
![]()
Seb (Navigateur = DOM / SHadow Dom … )
https://www.w3.org/Provider/Style/URI
HyperText Transfer Protocol (HTTP)
Exemples simple : http://web.simmons.edu/~grovesd/comm244/notes/week4/document-tree.
REF : https://zenodo.org/records/3707008#.X6XOHVMzbDo
Le contenu de la page (HTML) est stocké par le navigateur sous forme d’une hiérarchie de nœud.
Reference : https://www.w3.org/TR/DOM-Level-3-Core/introduction.html
La structure du document en elle même est dénommée DOM Tree, mais ce qui nous intéresse le plus c’est le DOM (Document Object Model ). Le DOM contient le DOM Tree, mais pas seulement, c’est une API[^1] simple et universelle, avec laquelle les programmes et l’utilisateur peuvent interagir (appliquer des styles, déclencher des événements, etc.) via l’intermédiaire d’un langage de script (Javascript[^2] ou autre).
Historiquement le DOM fait suite à Dynamic HTML ou DHTML dans les Navigateurs (1997, voir https://webdevelopmenthistory.com/1997-the-year-of-dhtml/). Ce standard apparait du fait de la nécessité conjointe, pour CSS, pour JS (1996) de manipuler, requêter le contenu structuré des documents HTML. En effet, sans DOM, le Javascript n’aurait pas d’élément, de page web à manipuler, c’est pourquoi à l’origine ils étaient étroitement liés.
Dénommé ensuite DOM - level 0 par le W3C, ce DHTML posait un certain nombre de problème c’est pourquoi le W3C a initié un groupe de réflexion en 1997 pour établir DOM comme une API standard, agnostique, ouverte, et donc utilisable pour n’importe quel langage ayant besoin d’accéder, manipuler un document structuré.
La norme s’est enrichi de nouvelles fonctionnalités au fil du temps, dont certaines comme XPath (2004) qui nous intéressent directement pour le webscrapping. On trouve une spécification détaillé du DOM en cours (DOM v4) sur les pages du W3C
Enfin, et c’est ce qui va nous intéresser le plus dans un premier temps, grâce à Javascript ou à des langage de requêtes (XPATH selector, CSS selector) il est possible de rechercher et d’extraire les éléments (ou données) qui nous intéressent dans cet arbre. Pour des raisons pédagogiques, nous traitons seulement partie Javascript dans cette section, XPATH et CSS Selector sont abordés en détail dans la section.
Pour expliquer les différents concepts lié au DOM nous allons partir d’un exemple très simple.
<!doctype html>
<html>
<head>
<title>Le Webscrapping</title>
</head>
<body>
<h1>Introduction</h1>
<p>Le Webscrapping est une méthode de récolte automatisé d'un contenu web</p>
<p>Les outils les plus utilisés sont : </p>
<ul>
<li>En Python : <a href="https://scrapy.org/">Scrapy</a></li>
<li>En R : R <a href="https://cran.r-project.org/web/packages/rvest/index.html">RVest</a></li>
</ul>
<p> Voilà, <b> c'est tout ! </b> </p>
</body>
</html>Ce code source HTML sera représentée dans la mémoire du navigateur sous la forme d’arbre DOM suivante :
flowchart
HTML
HTML --> HEAD
HEAD --> TITLE
HTML --> BODY
BODY --> H1 & P1[P] & P2[P] & UL & P3[P]
UL --> LI1[LI] & LI2[LI]
LI1 --> A1[A]
LI2 --> A2[A]
P3[P] --> B
Ce Tree (Arbre) est un Document fait d’un ensemble de Node (Noeuds) générique qui partage des propriétés communes. Ces noeuds ont des relations de hierarchies (parent, children, descendant, ascendant, next sibling, previous sibling ), ce qui qui permet de naviguer, circuler dans l’arbre assez aisément.
La structure de donnée de type arbre en informatique est une structure récursive très courante en informatique. Par récursif il faut entendre qu’un Noeud de l’arbre peut contenir soit : 0 Noeud (on parle leaf ou external nodes), soit un ensemble de Noeuds fils (internal nodes). Les noeuds sont reliés entre eux par des branches.
La terminologie reprise pour décrire le DOM ne fait que reprendre une grande partie de la terminologie courante pour ce type de structure de donnée.
Si on regarde plus en détail, ces NODE peuvent être de nature différentes, ils possèdent en effet des types (Node.nodeType) qui indiquent en quoi ceux-ci se différencient : ELEMENT_NODE, TEXT_NODE, DOCUMENT_NODE pour ne citer que les plus pertinents dans notre cadre.
NODE de sous-type TEXT_NODE signifie qu’il s’agit de texte et rien d’autre.NODE de sous-type ELEMENT_NODE signifie qu’il s’agit d’une balise HTMLDe part leur nature récursive, ces ELEMENT_NODE peuvent soit ne rien contenir, soit contenir des Noeuds fils (children).
Dans l’arborescence telle que calculée par live DOM viewer, les ELEMENT_NODE sont en violet, et les TEXT_NODE en gris.

Pour y voir plus clair, nous allons faire quelques manipulations de l’arbre avec l’aide de Javascript.
Le premier langage capable de manipuler le DOM est Javascript, avec de simple requête il devient possible d’extraire, d’ajouter, de modifier, de supprimer des éléments ou des attributs HTML.
Les codes préséent dans cette section peuvent tous être executé dans une Sandbox MSDN.
Cette partie donne quelques éléments principaux pour comprendre la suite, le lecteur plus curieux pourra se référer à la section Javascript.
Javascript, comme beaucoup d’autres langages de programmation (R, Python) s’appuie sur le paradigme Objet (Programmation Orienté Objet ou POO) pour structurer l’information de ces programmes.
En Javascript un objet est fait d’un ensemble de clefs et de valeurs qui sont représentée par le couple clef:valeur
Par exemple l’objet myBook contient les attributs author, title, year :
const myBook = {
author: "Sebastien R",
title: "boobook",
isbn: "31223212",
year: 1969,
};Les attributs peuvent être de tout type : chaine de caractère, numérique, tableau, objet, etc.
Pour accéder aux attributs de l’objet, on utilise une notation avec un point (myBook.author ) ou un crochet (myBook["author"]).
Il est aussi possible de définir des fonctions à nos objets. Dans cet exemple on définit deux fonctions addBook qui ajoute l’objet livre passé en paramètre (newBook) à l’attribut books, un tableau pour le moment vide définit ainsi en javascript : [] .
const myBook = {
author: "Sebastien R",
title: "boobook",
isbn: "31223212",
year: 1969,
};
const myLibrary = {
name: "L'échiquier",
books: [],
addBook: function( newBook ){
this.books.push(newBook);
console.log("pushed a new book")
},
countBook: function() {
console.log (this.books.length);
},
};Les fonctions et méthodes peuvent être appelée en utilisant la notation indicée suivante : nomdelobjet.nomdelafonction(paramètres).
myLibrary.countBook();
myLibrary.addBook(myBook);
myLibrary.countBook();Les attributs et les fonctions sont partout en Javascript, on les utilise parfois même sans le savoir. Par exemple pour afficher le contenu d’une variable, d’un attribut dans la console on utilise en général la fonction console.log(...), ce qui revient finalement in fine à appeler la méthode log(...) de l’objet console.
console.log(myBook.author)Et enfin il est possible d’accéder et de récupérer des objets stocké dans des objets via des tableaux. On modifie notre objet myLibrary pour qu’il retourne le livre correspondant au bon ISBN grâce à la fonction getABook()
// ... meme code que précédemment ...
const myLibrary = {
// ... meme code que précédemment ...
getABook: function ( isbnToFound ) {
let item = this.books.filter(b => b.isbn == isbnToFound);
return item.pop()
}
};
myLibrary.addBook(myBook);
var abook = myLibrary.getABook("31223212");
console.log(abook.author);Renvoie le résultat suivant :
pushed a new book
"Sebastien R"Mais nous aurions pu également directement accéder au tableau depuis l’attribut, sans passer par une fonction filtrant le catalogue de livres books, à condition de connaitre la position du livre …
console.log(myLibrary.books[0].author);Sachant cela, nous avons les éléments de compréhension nécessaire pour comprendre comment manipuler les différents éléments de notre arbre.
Pour récupérer l’ensemble des eléments HTML sous un Noeud, on peut utiliser la fonction children. Les éléments sont récupérés sous la forme d’une collection HTMLCollection dans laquelle on peut récupérer les élements soit en utilisant la fonction item(x), soit directement en utilisant la notation crochet [x]
const root = document.children;
console.log(root[0].children.length); // renvoie 2 éléments : Head, Body
console.log(root[0].children[1].children); // renvoie 5 éléments : h1, p, p, ul, p
let save_p = root[0].children[1].children[4]; // sauvegarde l'element p Si on questionne l’élément save_p, qui contient dans notre graphe à la fois un Noeud texte (“Voilà”) et un autre Noeud balise de type b (“c’est tout !”) avec la fonction children().
On se rend compte que celle-ci nous renvoie seulement les noeuds de type Node.Node_Element. Pour récupérer l’ensemble des Nodes, il faut faire appel à une autre fonction childNodes.
console.log(root[0].children[1].children[4].childNodes); // renvoie une NodeList avec un Node.Text_Node #text et un Node.Element_Node b
console.log(root[0].children[1].children[4].childNodes[1].childNodes[0].textContent); // renvoie le contenu du Node.Text_Node contenu dans bPour accéder aux éléments situé sur la même ligne hierarchique, ou dit plus simplement, existant dans la même collection de Noeuds, il est possible d’utiliser les fonctions nextElementSibling et previousElementSibling
let save_ul = root[0].children[1].children[3]; // renvoie l'element ul
console.log(save_ul.children[0].nextElementSibling.children[0].href) // renvoie https://cran.r-project.org/web/packages/rvest/index.html Les collections renvoyé par le DOM (HTMLCollection, NodeList, etc. ) ne sont pas des Array classique tel qu’on peut les avoir en Javascript. Pour les transformer en objet de type Array, et bénéficier de toutes les fonctions utilitaires qui vont avec, il faut les convertir avec la fonction Array.from()
Si nous souhaitons récupérer le parent d’un élément il suffit d’appeler parentElement ou parentNodes si on souhaite avoir les différents type de noeuds :
console.log(root[0].children[1].children[4].childNodes[1].parentElement); // renvoie le parent de b, à savoir pPour récupérer l’ensemble des Elements de type p nous pouvons nous appuyer sur la méthode getElementsByTagName():
let searchedTags = Array.from(document.getElementsByTagName("p"));
searchedTags.forEach((element) => console.log(element.textContent));Ce code permet de lister le contenu d’un objet HTMLCollection avec une boucle. Une HTMLCollection est un tableau composé d’élements HTMLElement de type <p> ou HTMLParagraphElement. Ce qui affiche le contenu suivant.
Le Webscrapping est une méthode de récolte automatisé d'un contenu web
Les outils les plus utilisés sont :
Voilà, c'est tout !Il est aussi possible d’ajouter des nouveaux Element à cet arbre de façon dynamique, par exemple si on désire ajouter un nouvel élement <p> à notre document HTML :
let searchedTags = Array.from(document.getElementsByTagName("p"));
let newElement = document.createElement("p");
newElement.textContent = "En fait j'avais oublié quelque chose !";
let lastElementP = searchedTags[searchedTags.length - 1];
lastElementP.parentNode.insertBefore(newElement, lastElementP);Nous allons refaire cette manipulation depuis le navigateur : - Ouvrez la page toy statique. - Ouvrez les outils Web Developper Tools : ceux-ci sont accessibles l’on fait un clic droit n’importe ou sur la page, puis en selectionnant l’option Inspecteur - Mettez vous sur l’onglet Console de cette nouvelle fenêtre ouverte en bas de votre écran. - Copiez/Collez le bout de code javascript précédent et appuyez sur Entrée

Normalement votre contenu HTML devrait changer ainsi :

Maintenant nous allons inspecter le code source du document via l’outil Inspecteur
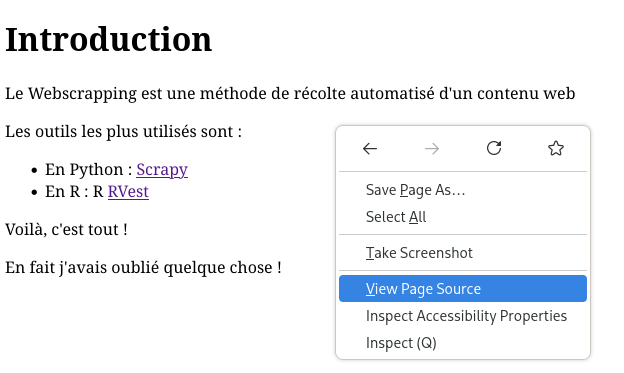
Ce qui nous ainsi de constater un élément important, en effet le code source HTML n’a pas changé :

Le code source et donc le fichier de la page HTML original n’est pas modifié par le code, c’est seulement sa représentation en mémoire qui est modifié.
TODO : Fournir un exemple simple, de bout en bout : HTML, DOM, XPATH , s’appuyer la dessus : https://software.hixie.ch/utilities/js/live-dom-viewer/ et le doc de référence : https://dom.spec.whatwg.org/#introduction-to-the-dom
Si nous faisons abstraction du flou qui accompagne l’usage du terme “Web 2.0”[^3], et que l’on se concentre plus sur les nouveautés techniques qui sont apparus dans cette période des années 2000, alors il faut évoquer la remise en cause du schéma classique synchrone entre client et serveur. La démocratisation des technologies regroupées sous le nom d’AJAX (Asynchronous JavaScript And XML) permet l’échange d’informations entre le navigateur et le serveur sans que le serveur n’ait besoin de renvoyer l’entièreté de la page (circulation asynchrone des données).
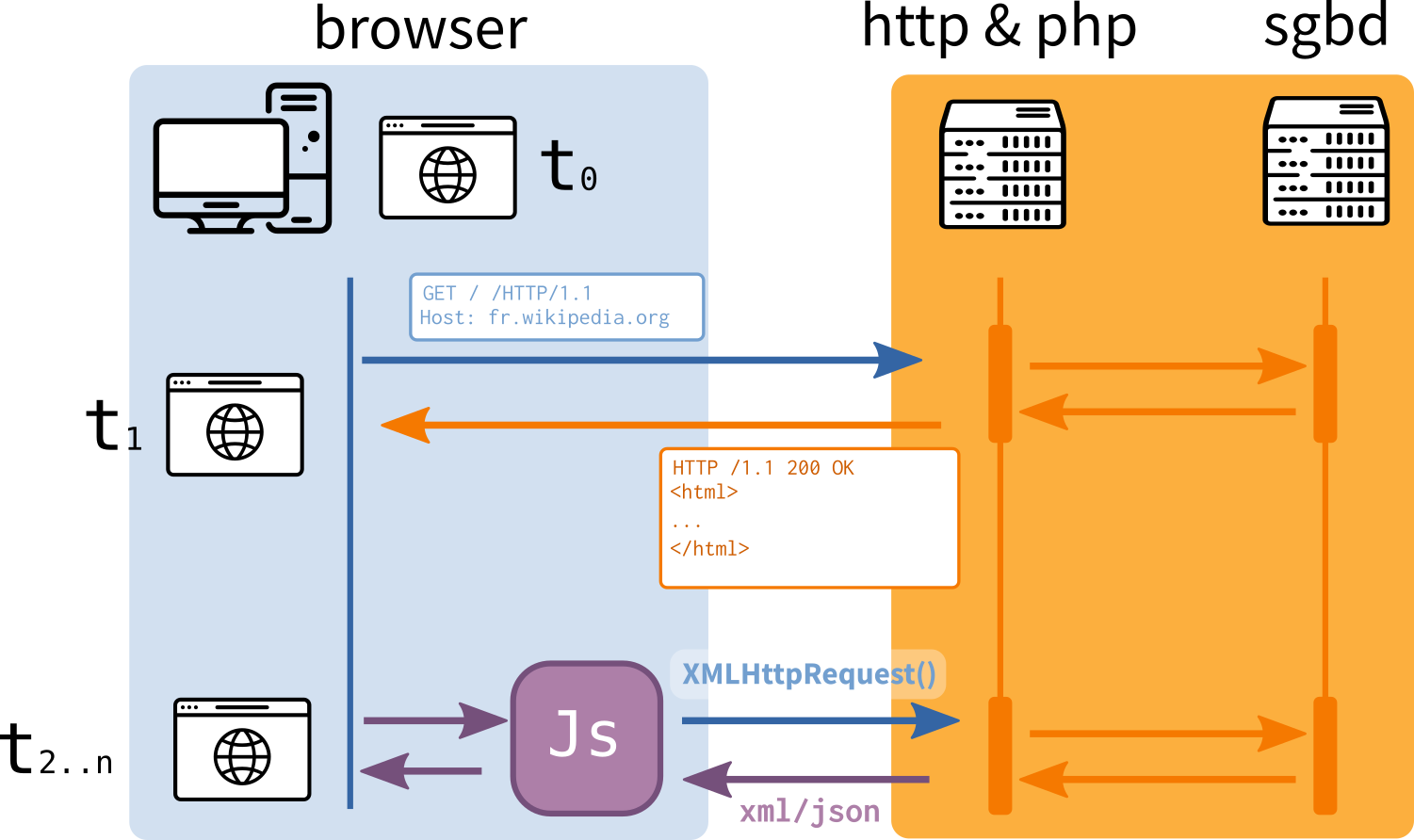
Le serveur HTTP fournit la partie html/css/js (“frontend”) qui s’affiche dans le client navigateur, mais une partie de ce html/css/js, peut être à la fois générée par le serveur (“backend”), et a posteriori par le navigateur de façon dynamique en fonction de requêtes (XMLHttpRequest() ou XHR) déclenchées par les actions utilisateurs en temps réel. Ainsi, le code source de la page web récupéré à un instant t ne contient pas nécessairement l’information définitive. Cette capacité est utilisée pour diverses raisons (rapidité d’affichage, interactivité, etc.) et sert aussi de support à des requêtes en provenance d’API.
WIP, j’ai repris du contenu existant, ca devrait pas mal bouger.
voir les deux pages https://css-tricks.com/the-ecological-impact-of-browser-diversity/#article-header-id-0 et https://css-tricks.com/browser-engine-diversity/ pour comprendre l’intérêt de maintenir cette diversité.↩︎
une diversité d’acteurs et d’objectifs dont on trouve un récit ici, dans l’historique du développement de CSS GRID, un standard développé par des acteur et des fonds extérieurs à la plateforme : https://bkardell.com/blog/Beyond.html↩︎
Le premier proposal est en ligne sur cette page https://www.w3.org/History/1989/proposal.html↩︎
Ted Nelson théorisera aussi les notions d’HyperMedia, de transclusion, de virtuality, d’intertwingularity, etc.↩︎
Si la vision des promoteurs de Xanadu a très largement essaimé, le système et ses rouages prévu, trop complexes pour leur temps, n’ont jamais été achevé complétement. Pour certains c’est aussi une question de copyright, le code source des prototypes (libéré sous le nom de Udanax Green et Gold ici http://udanax.xanadu.com/) n’a été libéré que très tardivement en 1999, le projet original Xanadu restant encore sous secret. Les spécifications de 1984 ont été retrouvé et libéré sur ce site : https://sentido-labs.com/en/library/201904240732/Xanadu%20Hypertext%20Documents.html. Une destinée asez similaire à celle qu’a connu Charles Babbage avec ses machines…
Today’s one-way hypertext– the World Wide Web– is far too shallow. The Xanadu project foresaw world-wide hypertext decades ago, and endeavored to create a much deeper system. The Web, however, took over with a very shallow structure.
Src: https://xanadu.com/xuTheModel/index.html↩︎