h2 {
font-size: 25px;
}
p {
color: #008080;
font-family: Arial, sans-serif;
}
a {
text-decoration: none;
color: #0000ff;
}HTML & CSS
L’extraction automatisé de données du web requiert des prérequis indispensables : certaines connaissances spécifiques liées à la structure d’une page web et une compréhension des principes techniques sous-jacents. Vous devez ainsi acquérir une connaissance du langage HTML (balises) et une familiarité avec le CSS (sélecteurs) pour identifier, cibler et extraire les éléments d’une page web.
Le language HTML
Le HTML, acronyme de HyperText Markup Language (langage de balisage hypertexte en français), est un langage informatique utilisé pour structurer et organiser le contenu des pages web.
Bref historique
HTML (HyperText Markup Language) mais aussi par la suite XML (Extensible Markup Language) sont inspiré d’une application de SGML utilisé au CERN, le premier document connu, présenté ci-dessous, date du 3 décembre 1990.
<h1>Standardisation</h1>
There was not a lot of discussion of this at <a href=Introduction.html>ECHT90</a>, but there seem to be two leads:
<ol>
<li><a href=People.html#newcombe>Steve newcombe's</a> and Goldfarber's "Hytime" committee
looking into SGML, and
<li>An ISO working group known as MHEG, "Multimedia/HyperText Expert Group".
led by one Francis Kretz (Thompsa SA? Rennes?).
</lo>Comme on peut le voir dans cet exemple, HTML est un langage de balise qui intègre des symboles et des tags (markup) structurant le document texte original en y ajoutant des informations supplémentaires sous une forme purement logique. Dans sa première spécification en 1991[^6], HTML-0 ou _HTML Tags_on trouve 22 tags uniquements logiques. Ainsi <h1> indique qu’il s’agit d’un “élément de titre de niveau 1”, mais cela ne dit rien sur la façon, la forme dont il sera présenté au lecteur. Ce qui paraissait être un défaut au départ, c’est à dire l’absence d’information sur la forme (gras, italique, souligné, etc), sera une grande force de part la flexibilité que ce niveau d’abstraction supplémentaire procure.
Les balises
Le HTML utilise une syntaxe basée sur des balises (tags) pour délimiter les différents éléments d’une page. Chaque balise est entourée des symboles < et > et peut contenir des attributs qui spécifient des propriétés supplémentaires pour l’élément.
Si aucune balise n’est obligatoire dans une page HTML, il est de convention d’avoir la structure de base suivante :
<!DOCTYPE html>
<html>
<head>
<title>Titre de la page</title>
</head>
<body>
<!-- Contenu de la page -->
</body>
</html><!DOCTYPE html>: en début du document, indique au navigateur qu’il s’agit d’une page HTML5.<html>: englobe tout le contenu de la page HTML.
<head>: contient les métadonnées de la page, des liens vers des fichiers annexes (CSS, javascript…), etc.
<title>: pour définir le titre de la page qui apparaîtra dans la barre de titre du navigateur.<body>: contient tout le contenu visible de la page, tel que le texte, les images, les liens, les tableaux, etc
Dans la majorité des cas, on utilise une balise de fermeture en indiquer la fin. Une balise de fermeture présente un / avant le nom de la balise pour indiquer la fin de l’élément :
<body>
<!-- Contenu de la page -->
</body>Le body peut contenir toute une variété de balises prédéfinies pour structurer et ajouter différents types de contenu dans la page web. Voici quelques balises indispensables à connaitre :
• <h1> à <h6> : balises de titres de différents niveaux, <h1> étant le plus important.
• <p> : balise de paragraphe pour le texte.
• <a> : balise de lien hypertexte pour créer des liens vers d’autres pages ou ressources.
• <img> : balise pour l’insertion d’images.
• <ul> et <li> : balises pour créer des listes à puces ou numérotées.
• <table>, <tr>, <td> : balises pour créer des tableaux avec des lignes et des cellules de données.
• <div> et <span> : balises génériques utilisées pour diviser et grouper le contenu.
Exemple de balise p (paragraphe) :
<body>
<p>Un paragraphe en langage HTML</p>
</body>Dans cet exemple, la balise <p> représente un paragraphe dont le contenu “Un paragraphe en langage HTML” est placé entre la balise d’ouverture <p> et la balise de fermeture </p>.
Les attributs
Ces balises hiérarchisées et potentiellement regroupées, peuvent être accompagnées d’attributs qui permettent de spécifier des informations supplémentaires, tels que des identifiants (id), des classes (class), des liens (href), etc. Ces attributs sont à spécifier dans la balise d’ouverture :
<body>
<div id="header">
<h1 class="category">Tous les articles</h1>
</div>
<div id="Liste_ref">
<h2 class="article">Titre article</h2>
<p class="summary">Résumé de l'article...</p>
<a href="https://www.article.org">Intégralité de l'article</a>
</div>
</body>L’organisation segmenté du contenu via les balises div ou span ainsi que les différents attributs spécifiés permettent la mise en forme et le paramétrage des éléments. Mais la structure de la page ainsi que les attributs spécifiés sont également des éléments cruciaux pour la collecte automatisée de données sur le web.
La language CSS
Le CSS, ou Cascading Style Sheets (feuilles de style en cascade), est un langage de programmation utilisé pour décrire l’apparence et la mise en forme des documents HTML et XML. Il permet de contrôler l’apparence visuelle des différents éléments de pages web (taille, position, couleur, police, marges, etc.) via les sélecteurs CSS.
Bref historique
HTML est censé représenter la structure et le contenu de la page web, et c’est le langage CSS ( Cascading Style Sheets) qui permet sa mise en page. Cette volonté de séparer le contenu et sa présentation n’est pas récente, et à vrai dire elle était déjà inclus dans le premier navigateur WorldWideWeb
Tim Bernard Lee n’a toutefois pas été jusqu’à proposer ou imposer une spécification ou un standard dans ce domaine. C’est pourquoi lorsque CSS (Cascading Style Sheets) apparait au CERN en 1994, ce n’est pas pas le seul langage pour mettre en forme HTML, chaque navigateur ayant développé son propre langage. La première proposition de CSS1 date de 1994, mais il faudra attendre décembre 1996 pour qu’une première recommandation CSS1 émerge du W3C. L’année d’après un vrai groupe de travail est mis en place au W3C pour travailler sur la suite des spécifications CSS2 et 3.
A l’origine de CSS on retrouve deux personnes, Bert Bos et Hakon Wium Lie. Les éléments historiques cités ici sont pour la plupart tirés de (Lie et Bos. 1999) et de sa thèse écrite a posteriori sur CSS en 2005 (Lie 2005).
C’est ainsi que l’on apprendre l’origine du terme Style Sheets. Dans le monde de l’édition traditionnelle il s’agit d’un ensemble de règles associées au document pour garantir sa cohérence. Le terme suivra l’évolution des pratiques et avec le passage à l’édition éléctroniques (Lie 2005) nous indique :
Combined with structured documents, style sheets offered late binding [Reid 1989] of content and presentation where the content and the presentation are combined after the authoring is complete. This idea was attractive to publishers for two reasons. First, a consistent style could be achieved across a range of publications. Second, the author did not have to worry about the presentation of the publication but could concentrate on the content.
A set of rules that associate stylistic properties and values with structural elements in a document, thereby expressing how to present the document. Style sheets generally do not contain content; are linkable from documents; and are reusable.
Pour son usage dans le web, la définition de (Lie 2005) pour style sheet est la suivante :
[…] style sheet is defined as a set of rules that associate stylistic properties and values with structural elements in a document, thereby expressing how to present the document.
Par late binding il faut comprendre que l’opération de style opère après que l’auteur ait validé le manuscript. Sur le Web, (Lie 2005) parle même de later binding car la stylification opère non plus chez l’éditeur mais dans le Navigateur web, ce qui permet d’appliquer la mise en forme proposée par la feuille de style, puis en cascade les préférences de l’utilisateur.
Ce qui nous intéressera plus particulièrement dans les CSS c’est la possibilité de récupérer du contenu en s’appuyant sur le style défini dans les attributs des balises HTML. Il n’est pas évident de comprendre ce qu’est un selecteur, (Lie 2005) donne la définition suivante :
Selectors: selectors specify which elements are to be influenced by the style rule. As such, selectors are the glue between the structure of the document and the stylistic rules in the style sheets.
Dans l’exemple suivant, qui définit une règle de style, H1 est le selecteur, et la déclaration est font-size
H1 { font-size: 2em }Les selecteurs ajoutées par la suite dans la version CSS2 permettent d’aller beaucoup plus loin en terme de requêtes pour récupérer du contenu. Certaines sont illustrées dans la suite de ce document.
Astuce
Pour mieux comprendre les mécanismes des sélecteurs il faut se représenter la structure des pages tels qu’elles sont stockées en mémoire dans le navigateur, c’est à dire sous forme d’arbre (__tree_), une structure de données hierarchique bien connue en informatique. Le DOM (Document Object Model) est une interface de programmation (API) interne au Navigateur qui permet de requêter les éléments de cet arbre, et cela de façon agnostique à tout langage (Javascript, CSS, XPath, etc.). Vous trouverez plus d’information sur cette API et le Navigateur dans la section.
HTML + CSS
Le CSS peut être incorporé de différentes manières :
- directement dans le document HTML, via la balise
<style>adapté à cet effet :
<style>
h1 {color:#f03b35;
font-size: 20px;}
</style>
<body>
<h1>Titre principal</h1>
</body>- dans le document HTML, directement dans les balises à l’aide de l’attribut
style:
<h1 style ="font-size:20px;color:#f03b35;">Titre principal</h1>- dans une feuille de style externe avec l’extension de fichier
.css:
<!DOCTYPE html>
<html>
<head>
<title>Titre de la page</title>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<h2>Titre article</h2>
<p class="summary">Résumé de l'article...</p>
<a href="https://www.article.org">Intégralité de l'article</a>
</body>
</html>Cette méthode est à privilégier car la séparation du contenu et la mise en forme facilite la mise à jour des styles.
CSS selector
Plusieurs sélecteurs CSS permettent de cibler et styliser les différents éléments HTML :
- Sélecteur d’élément : permet de cibler tous les éléments d’un certain type.
<h2> Titre d'exemple </h2>h2 { font-size: 20px;}- Sélecteur d’identifiant : permet de cibler un élément spécifique par son identifiant (
id).
<div id="example">
</div>#example {
background-color: #f2f2f2;
}- Sélecteur de classe : permet de cibler les éléments ayant une classe spécifique (
class).
<p class="summary">Ceci est un résumé</p>.summary {font-family: Arial, sans-serif;}- Sélecteur d’attribut : cible les éléments ayant un attribut spécifique. Exemple : l’attribut
href(lien cliquable)
<a href="https://www.example.org">Lien</a>a[href] { color: purple;}Il est possible de préciser sa cible en indiquant une valeur pour l’attribut.
<a href="https://www.example.org">Lien</a>a[href="https://example.org"] { color: purple;}En plus des sélecteurs simples, le CSS met à disposition des sélecteurs complexe et combinateurs que l’on peut utiliser pour cibler des contenus de manière très précise. Quelques exemples :
- Sélecteur descendant : cible les éléments qui sont descendants d’un autre élément.
<div id="liste_ref">
<p class="summary">Ceci est un résumé</p>
</div>#liste_ref p .summary { font-size: 12px; }Cible tous les paragraphes de la classe summary, positionnés dans l’élément ayant pour identifiant liste_ref.
- Sélecteur de voisin direct : cible les nœuds qui suivent immédiatement un élément
<div id="liste_ref">
<h2>Titre de l'article</h2>
<p class="summary">Ceci est un résumé</p>
<h2>Titre de l'article</h2>
<p class="summary">Ceci est un résumé</p>
</div>#liste_ref + h2 { font-size: 14px; }Cibler uniquement la première balise h2 de l’élément ayant pour identifiant liste_ref.
Note
Bien que la connaissance approfondie du CSS ne soit pas nécessaire le scraping, il est important de connaître les sélecteurs CSS. L’utilisation de ces sélecteurs est précieuse pour cibler des données de manière très précise et optimiser la collecte.
Code source HTML
La connaissance du HTML et du CSS vous permettra de comprendre et de naviguer dans le code source du page web.
Comment accéder au code source d’une page web ?
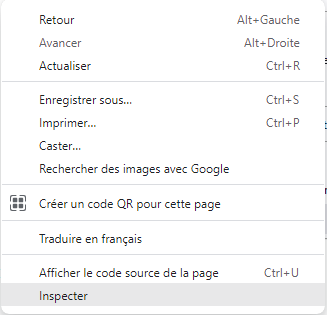
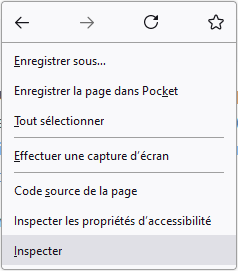
L’ensemble des navigateurs web modernes proposent des outils d’inspection du code source des pages web. L’inspecteur permet d’explorer le code source d’une page web en direct. Il facilite l’identification des balises, des classes, des identifiants et des styles associés aux éléments, et permet ainsi de procéder à une extraction ciblée de données. En utilisant l’inspecteur de code source, vous accédez à toutes les informations nécessaires pour concevoir un script de scraping. Pour y accéder, cliquez-droit n’importe où sur la page web ciblée, puis cliquez sur “Inspecter” :
Avec Google Chrome :
Avec Mozilla FireFox :
Récuperer un élément d’un page web
La connaissance des balises HTML et des sélecteurs CSS permet de comprendre la manière dont on construit une page web dont on la met en page, mais elle permet aussi, dans le contexte du scraping, de récupérer des éléments d’une page web pour en extraire le contenu.
Généralités sur la sélection d’éléments HTML
Dans le cadre d’un projet de scraping, illustré dans les parties suivantes, on utilisera le plus souvent un langage de programmation externe pour interroger un site web, en extraire des éléments et restructurer le contenu de ces derniers en vue de créer une base de données structurées.
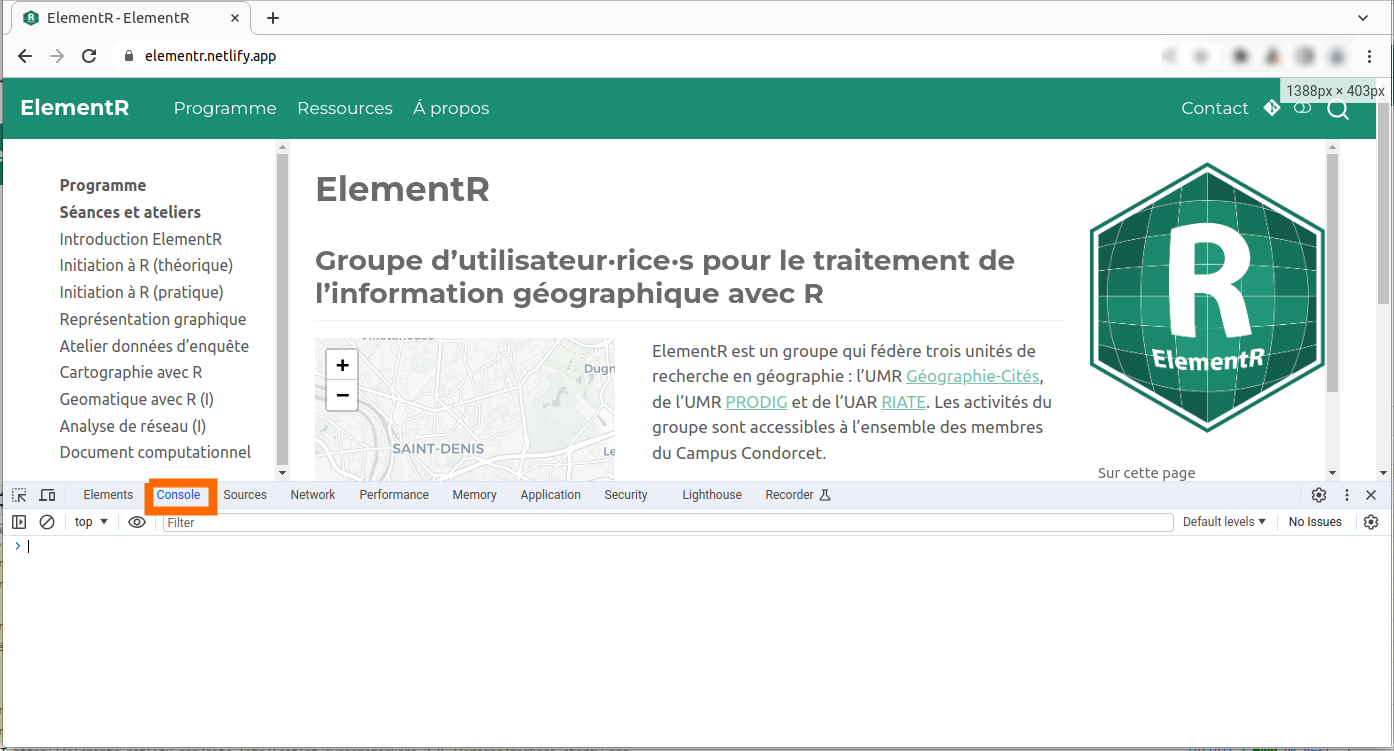
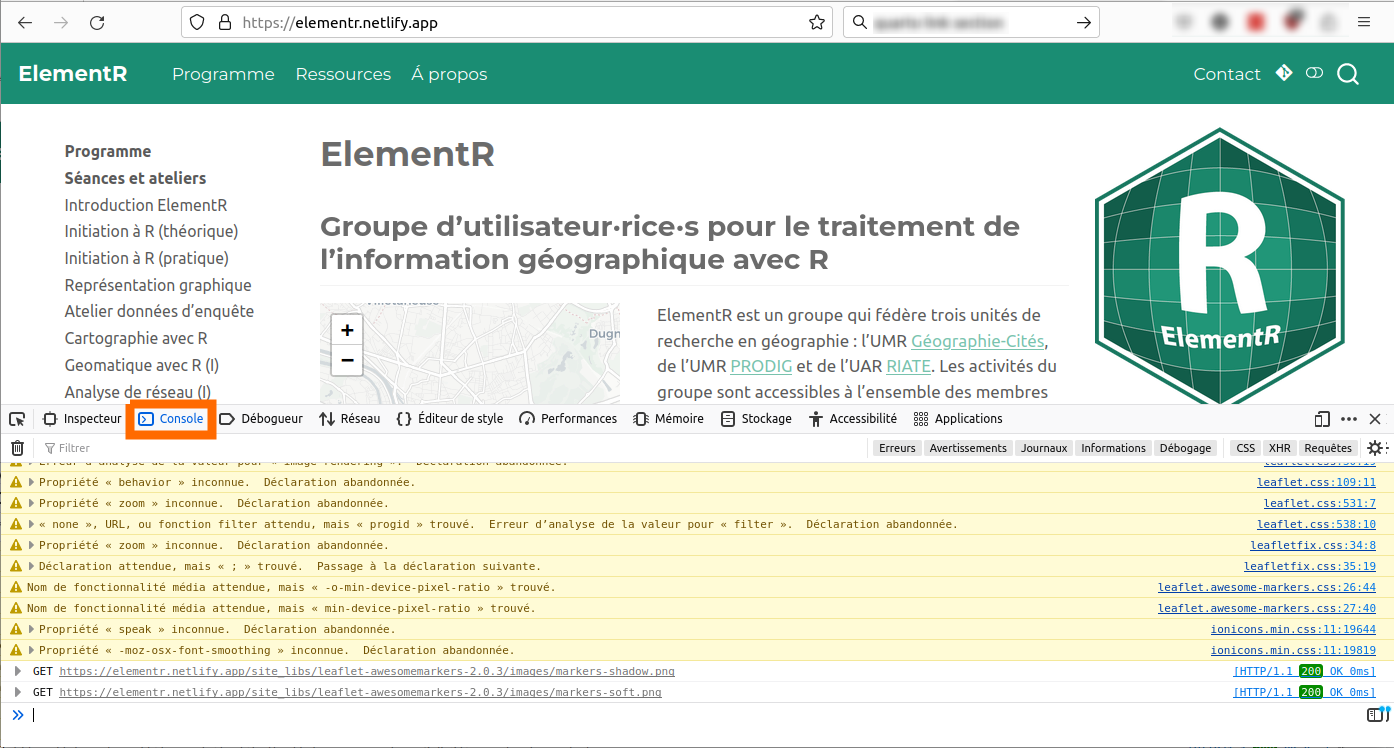
Toutefois, pour un premier aperçu de la manière dont on peut extraire du contenu depuis un site web, nous procéderons dans un premier temps au sein du navigateur web, via l’onglet Console des outils de développement (onglet présent le plus souvent à côté de l’onglet Inspecteur abordé dans la partie dédiée).
Avec Google Chrome :
Avec Mozilla FireFox :
La Console permet d’exécuter des requêtes javascript, et ainsi, d’interagir avec une page web. Avant de chercher à automatiser une collecte, une bonne pratique consiste donc à vérifier les requêtes dans le navigateur et sa console.
Dans celle-ci, on interagit avec la page web en javascript, en utilisant notamment les fonctions getElementBy(getElementById, getElementsByClassName, getElementsByTagName).
Un raccourci pratique, utilisant le symbole $ et permettant d’effectuer des requêtes sur les identifiants, les classes et les types, est disponible dans tous les navigateurs récents :
$('SelecteurCSS');
$x('SelecteurXPath');Sélection via sélecteurs CSS
Avertissement
RC : En attendant de créer un site dédié, j’exemplifie sur le site de ElementR
Pour tester cet outil de requête, nous pouvons chercher à isoler des informations tirées du site du groupe ElementR, et en particulier de la page du programme.

Dans cette page, on retrouve un tableau des séances passées et futures, que l’on peut chercher à extraire.
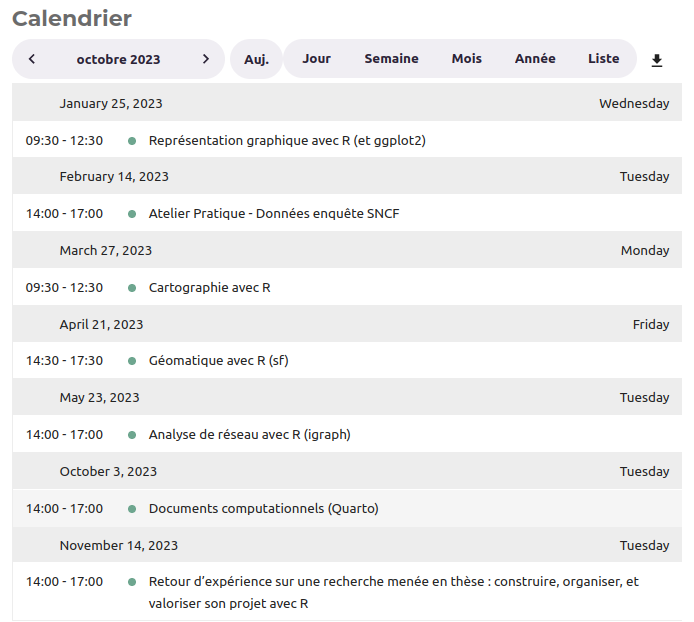
En inspectant le contenu de la page, on se rend compte que le tableau en lui-même est contenu dans une balise table, dont la classe est fc-list-table :
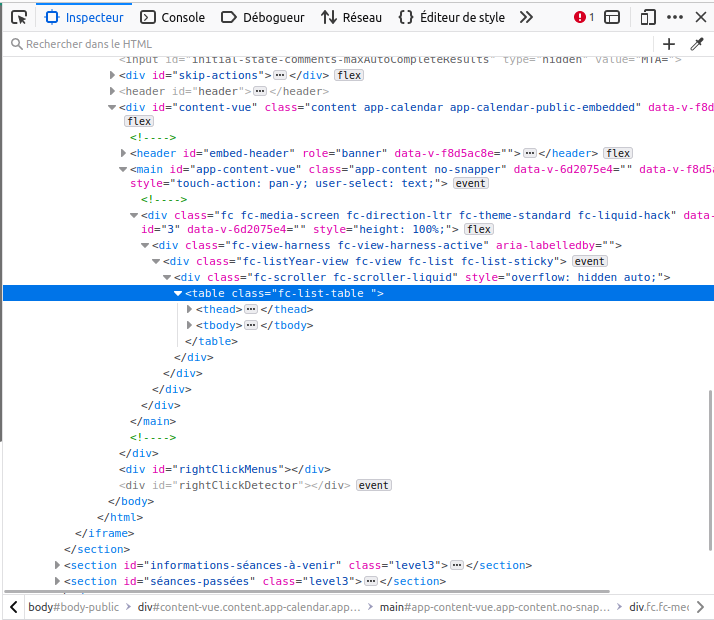
On va donc chercher à isoler ces éléments dans une requête css, dont la syntaxe sera :
$('table.fc-list-table');Dans la console, cela renvoi un sélecteur, dont on peut isoler le premier élément de réponse avec l’opérateur d’index : [0]
$('table.fc-list-table')[0];En
Sélection via sélecteurs XPath
Exercice
Hugues
Je propose de finir cette sous-partie avec le site web exemple et sur-mesure que l’on peut faire consulter (code source).
N’hésitez pas à modifier directement ou faire des retours.
Les références
Lie, Håkon Wium. 2005. « Cascading Style Sheets ». Thèse de doctorat, University of Oslo.
Lie, Håkon Wium, et Bert Bos. 1999. Cascading Style Sheets: Designing For The Web. Addison Wesley.